Learning Graph Representations with Embedding Propagation 정리
by Sangheon Lee
Learning Graph Representations with Embedding Propagation 정리
- 저자 : Alberto García-Durán, Mathias Niepert
- 학회 : NIPS 2017
- 날짜 : 2017.10.09
- 인용 : 29회
- 논문 : paper
서론
- Graph data를 vector에 mapping하는 기법.
- 기존 기법 : Embedding Propagation (EP)
- Unsupervised learning.
- 주변 node 사이에서 message passing을 통해 graph의 vector representations(embeddings)을 학습함.
제안 모델
- 저자의 제안 기법 : EP-B
- loss function의 modify.
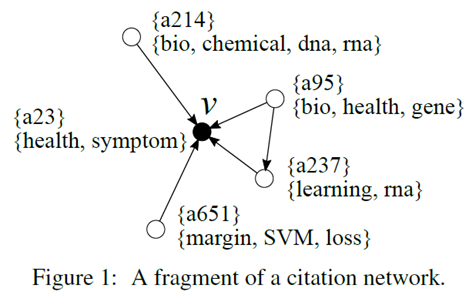
- 위와 같이 label이 여러개고, 각 label마다 label을 결정하는 값들도 여러개일 때, label 종류 별로 embedding을 따로 하는 방식.
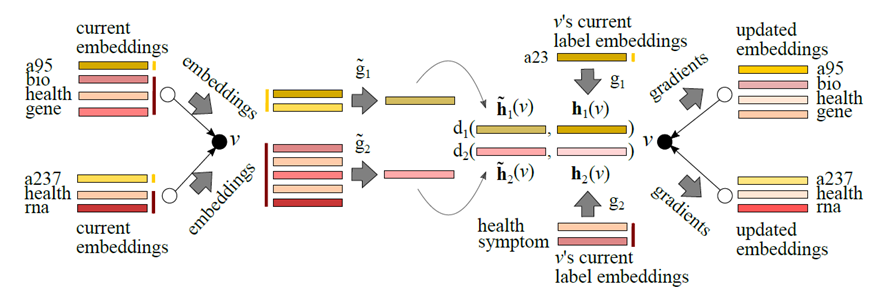
- 위의 그림이 저자의 제안 기법.
- 한 node의 embedding 값을 결정하는 건 그 node의 label 단어들의 embedding값들. h1(v)
- v와 v의 이웃node 사이 edge에 대해, 이웃한 모든 node의 label을 합쳐서, label당 하나의 embedding 값을 만듦. h1~(v)
- 현재 v의 embeddimg 값(h1(v))과 v의 이웃 node에 의해 생성된 embedding 값(h1~(v))의 distance를 계산하고, 이를 역전파함으로써 v의 이웃 node의 embedding 값을 update함.
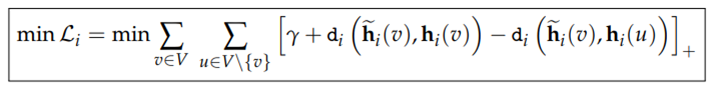
- 위는 저자 제안 기법의 loss function.
- ’+’ 값만 고려하는 것이기 때문에, v와 이웃하지 않은 node사이 거리보다 v와 이웃한 node사이 거리를 더 작게하는 방향으로 update됨.
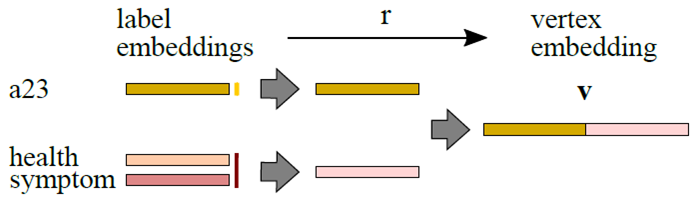
- 이렇게 각 node별로 label의 embedding값이 어느 정도 학습을 통해 정해지면, 그 node의 vector 표현은 그냥 label embedding값을 concatenate함.
실험
- ‘graph를 vector로 얼마나 잘 표현했는가?’에 대한 지표로, 기법을 통해 만들어진 vector 값을 이용하여 label의 classification 실험을 진행함.
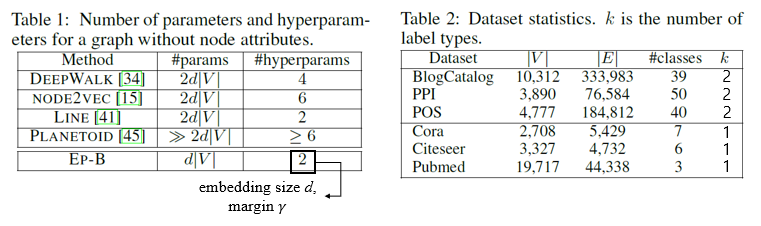
- 위는 실험에서 비교 평가한 model의 hyperparameter 수 및 dataset의 구성. EP-B 모델의 hyperparameter수가 2개로 굉장히 적고, parameter수도 적음을 알 수 있다.

- 위는 실험 결과. Single-label classification에 대한 결과 표인데, EP-B 모델의 성능이 가장 좋거나 다른 state-of-the-art model과 유사함을 알 수 있다. Multi-label classification 실험 결과 또한 비슷하게 나타났다.
논의
- node의 update 순서가 성능에 매우 중요한 영향을 줄 것 같은데, 이부분에 대해서는 논문에 언급되지 않았다.
- model의 성능 평가 실험에서, vector representation data를 이용한 classification이 과연 성능을 나타내는 좋은 실험일까?
- 만들어진 vector들이 기존 graph를 얼마나 잘 표현했는가를 측정하는 실험 또는 도표가 필요하다.
Subscribe via RSS
{kind=link}